neo.one Model Latency Performance
Dubverse’s neo.one model demonstrates exceptional performance in Text-to-Speech (TTS) generation, offering a balance of speed and quality comparable to industry-leading neural voice models. Here’s a detailed breakdown of its latency metrics and key features.Understanding TTS Latency
In the context of TTS technology, latency refers to the delay between receiving the input text and generating the audio output. It’s crucial to measure and optimize various comonents of latency for the best user experience.Components of Latency
- Network Latency: The time it takes for your request to reach Dubverse’s servers.
- Time to First Byte (TTFB): The time from initiating the API request to receiving the first byte of audio.
- Audio Synthesis Latency: The time it takes to generate the complete audio response.
neo.one Latency Metrics
Characters per Second
- neo.one: 276.13 (average)
- Industry Comparison:
- Amazon Polly (Neural): 459
- LMNT: 337
- Microsoft Azure (Neural): 292
- Google Cloud TTS (Studio): 287
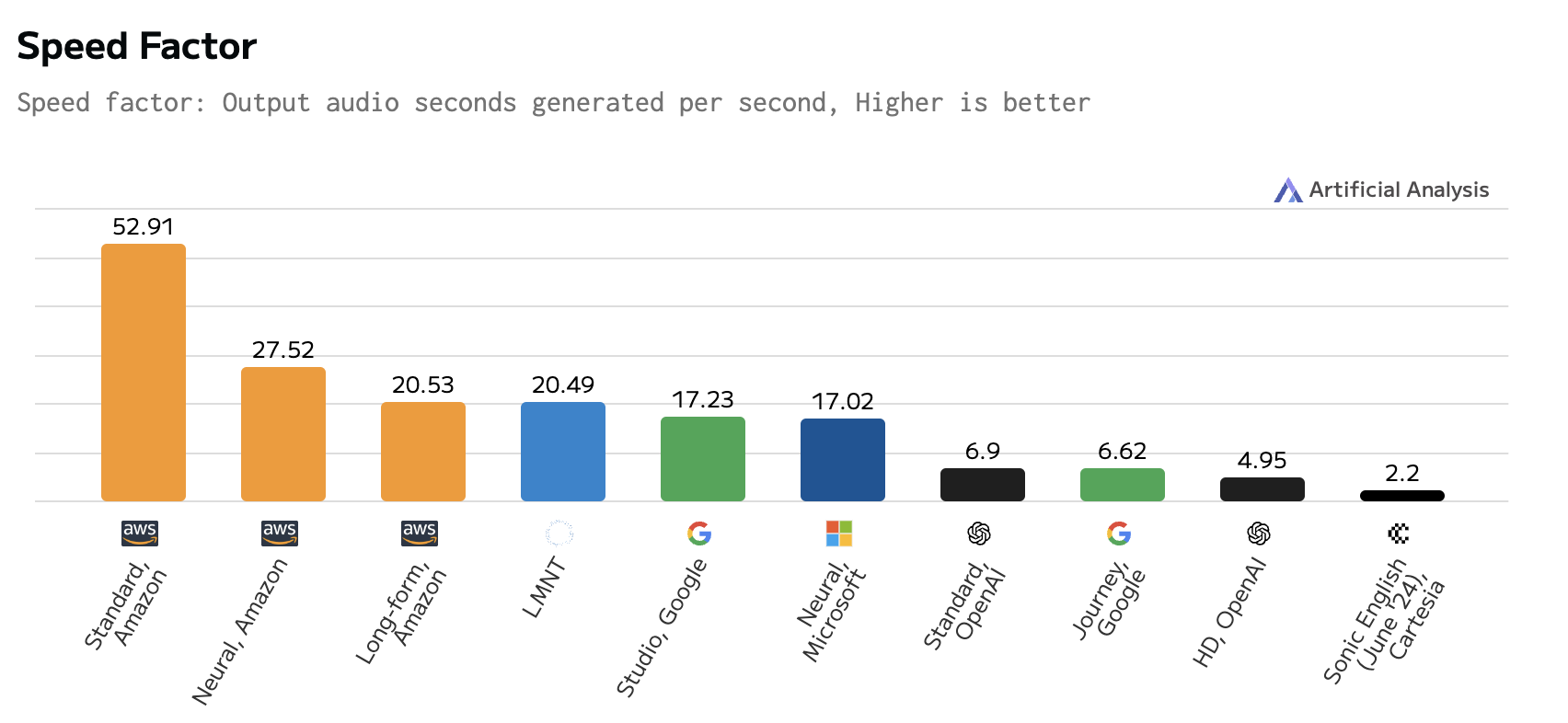
Speed Factor
- neo.one: 23.80x (average)
- Industry Comparison:
- Amazon Polly (Neural): 27.52
- LMNT: 20.49
- Google Cloud TTS (Studio): 17.23
- Microsoft Azure (Neural): 17.02
- Cartesia: 6.9x
These metrics are based on the report published by Artificial Analysis on October 17, 2024. For the full comparison, visit Artificial Analysis TTS Comparison.
Time to First Byte (TTFB)
- neo.one: 193.33 ms (average)
Key Features for Optimizing Latency
Streaming Support
neo.one supports audio streaming, allowing you to begin playback as soon as the first audio chunk is received. This significantly reduces perceived latency, especially for longer texts. Example of streaming implementation:Customizable Bitrate
neo.one allows you to adjust the bitrate of the audio output, balancing between audio quality and file size. Lower bitrates can reduce transmission time, further minimizing latency.Flexible Audio Formats
Choose from various audio formats to optimize for your specific use case, considering factors like quality, file size, and compatibility.Measuring Performance
To accurately measure neo.one’s performance, we provide a comprehensive testing script that calculates various metrics. You can use this script to replicate our results and test the performance in your own environment.Performance Testing Script
Performance Testing Script
- Replace
'YOUR_API_KEY_HERE'with your actual API key. - Run the script to test neo.one’s performance.
- The script will output various performance metrics, allowing you to compare with our reported averages.
Remember to handle your API key securely and not share it publicly.
Customizable Configuration
neo.one allows you to adjust various parameters to optimize for your specific use case. In theload dictionary of the test script, you can modify:
text: The input text for TTS conversionspeaker_no: The ID of the speaker voiceconfig: Additional configuration options, such as streaming settings
Tips for Minimizing Latency
- Text Chunking: For long texts, split content into smaller chunks and process them sequentially. This allows for faster initial playback.
- Optimize Server Location: Choose the server closest to your primary user base to reduce network latency.
- Caching: Implement caching strategies for frequently used phrases or responses to eliminate processing time for repeated content.
- Parallel Processing: For applications requiring multiple TTS conversions, consider implementing parallel API calls to reduce overall processing time.